这篇笔记主要分享我在开悟初赛中关于奖励设计的实战心得,尤其强调如何利用 `extra_info` 优化训练流程——它不能作为特征输入,却能巧妙融入奖励机制。我总结了几个关键技巧:默认对闪现技能施加负惩罚以控制使用频率,对BUFF奖励进行动态衰减避免过度依赖,并调整总奖励权重平衡各项激励。这些设计结合官方代码的适配改造(如通过布尔变量区分评估与训练阶段),帮助模型从零开始稳定收敛。
开悟初赛笔记-奖励设计篇
其实对于这种走迷宫找宝箱到终点的奖励设计,前面很多的大佬都已经发过很多相关的了。
我这边的话主要说下关于初赛奖励设计需要特别注意的地方,就是extra_info不能用作特征处理,但是可以用在奖励设计!
但是官方默认的代码会导致在评估的时候也调用了奖励处理的函数,所以你在里面运用会报错,其实在模型进行评估的时候是完全不需要调用奖励设计的。
如何在奖励设计的时候利用extra_info呢?这个的话我们需要给agenet.py
里面的 observation_process函数
提供一个额外的布尔变量去进行控制何时进行评估,何时进行训练即可,具体如下。
def observation_process(self, obs, extra_info=None, is_exploit=False):
if is_exploit:
feature, legal_action = self.preprocessor.process([obs, extra_info], self.last_action, is_exploit=is_exploit)
return ObsData(
feature=feature,
legal_action=legal_action,
)
else:
feature, legal_action, reward = self.preprocessor.process([obs, extra_info], self.last_action, is_exploit=is_exploit)
return ObsData(
feature=feature,
legal_action=legal_action,
reward=reward,
)
|
然后再把exploit函数对应的部分稍微更改下即可
@exploit_wrapper
def exploit(self, observation):
obs_data = self.observation_process(observation["obs"], observation["extra_info"], is_exploit=True)
feature = obs_data.feature
legal_action = obs_data.legal_action
probs, value = self.predict_process(feature, legal_action)
action, prob = random_choice(probs)
act = self.action_process(ActData(probs=probs, value=value, action=action, prob=prob))
return act
|
对应的preprocess.py里面的也同理
def process(self, frame_state, last_action, is_exploit=False):
self.pb2struct(frame_state, last_action)
...
if is_exploit:
return (
feature,
legal_action
)
else:
return (
feature,
legal_action,
reward_process(self._obs, self._extra_info, self.obs, self.extra_info, self.target, self.last_target, self.local_memory_map),
)
|
二、奖励设计
关于奖励设计,前面有很多大佬的优质帖子告诉了如何去设计奖励了,所以可以详细参考下他们的奖励设计然后运用到本次初赛里面。
【精华贴】海选阶段性总结
- 腾讯开悟社区平台
模型是怎么练成的
- 腾讯开悟社区平台
海选训练经验总结
- 腾讯开悟社区平台
海选训练思路总结
- 腾讯开悟社区平台
然后也可以看看我学习期的帖子,里面也大概写了一点关于奖励设计的。
开悟学习期笔记
- 腾讯开悟社区平台
总之大部分的奖励设计可以通过前面的帖子找到很好的灵感,然后我这边的话说下我的奖励设计对于今年可能比较特殊的部分。
1、闪现技能默认给惩罚
我的话默认给闪现奖励是负数的惩罚,因为想引导智能体能够合理的运用闪现,闪现的频率过高会扰乱智能体的进度。
2、BUFF获取奖励衰减
因为BUFF的话相对于其他的物件重要性偏低,我这边的设计是利用了总获取BUFF次数进行衰减的
reward_dict["buff_reward"] = buff_reward * math.pow(0.5, buff_cnt)
|
3、总奖励权重
其他的奖励其实没有做很多的创新,有些和我学习期的基本差不太多
reward_dict = {
"step_reward": -0.01,
"memory_reward": [-0.3 ~ -1.0],
"stop_reward": -0.5,
"talent_reward": -0.5,
"step_target_reward": 0.1,
"treasure_collected_reward": 5,
"buff_reward": 0.5 ** buff_cnt
}
|
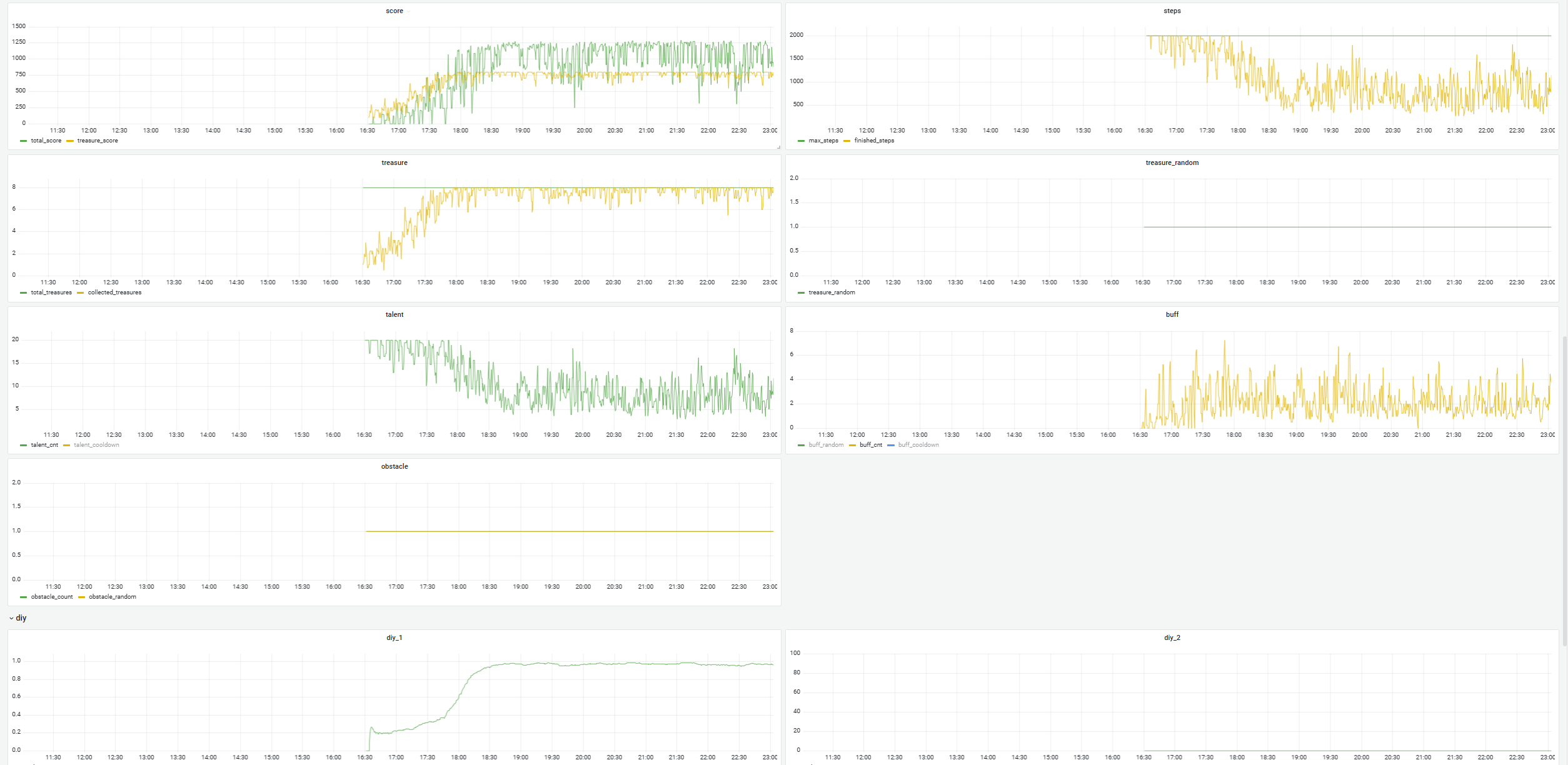
最终从零的PPO训练效果曲线如下: