
2025开悟学习期笔记

2025开悟学习期笔记
Crosery开悟学习期思路分享
一、问题分析
学习期的比赛环境是一个智能体在64x64的网格环境里面,宝箱是0-10的随机,位置也是随机的。比赛目的是为了能够让其在对地图不断地探索中学习移动策略,减少碰撞障碍物,以最少的步数从起点走到终点,可能会有附属任务——收集宝箱。
我们不妨把这个问题简化,我们把宝箱和终点都视为目标、终点可以看成一个特殊的目标。实际任务的本质就是
在这随机的目标(包括终点)里面,让智能体每次都走最近的目标,最后再到我们终点这个特殊目标
这样我们就可以把这个稍微复杂的问题分解成一个个小问题,无论在随机多少宝箱的环境,我们都能把它分解成每次都是以当前的位置到最近的目标的位置
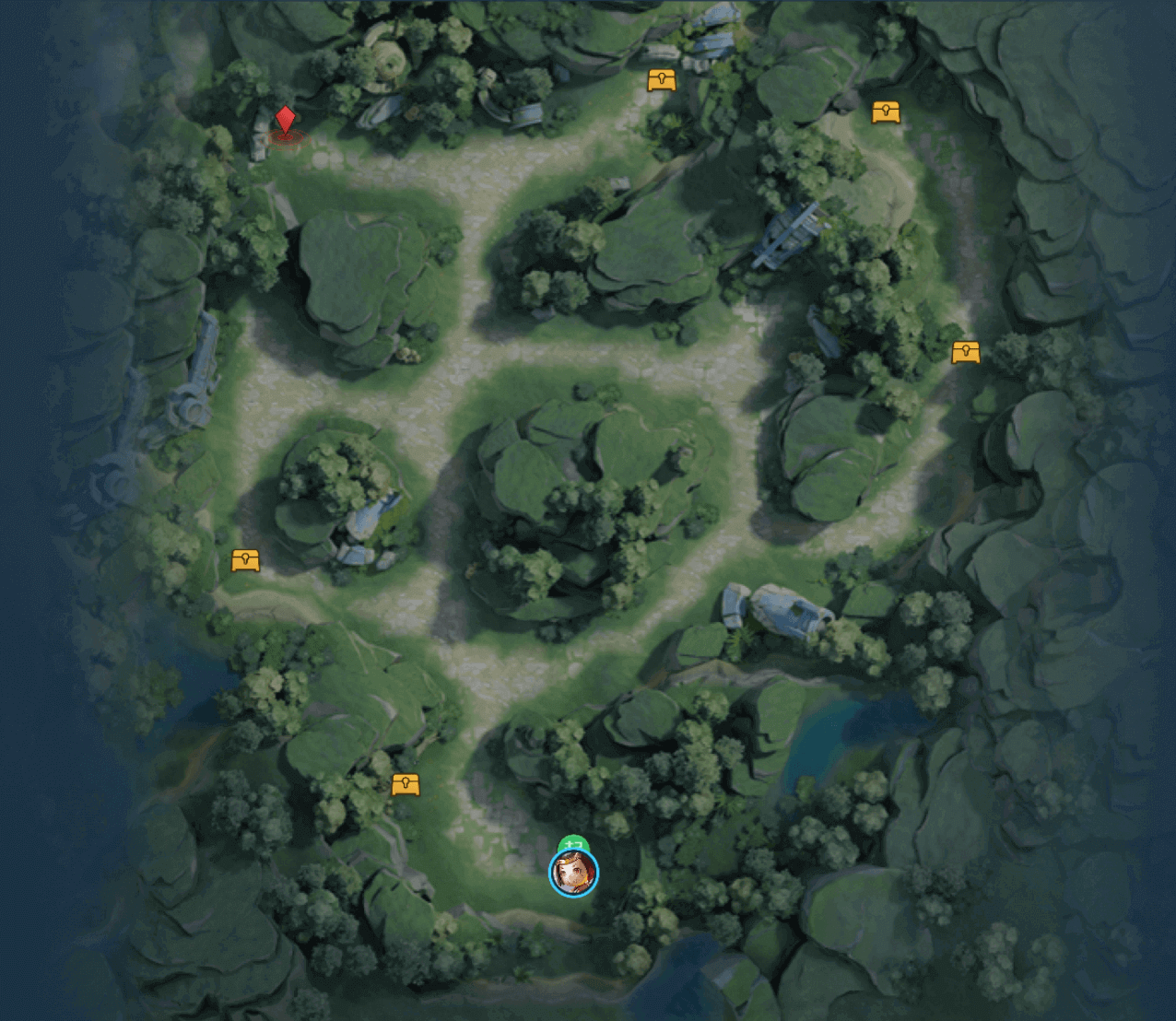
比如官方的这个示例图,我们就可以把它分解成6个任务。我们用红色箭头来标识如下图
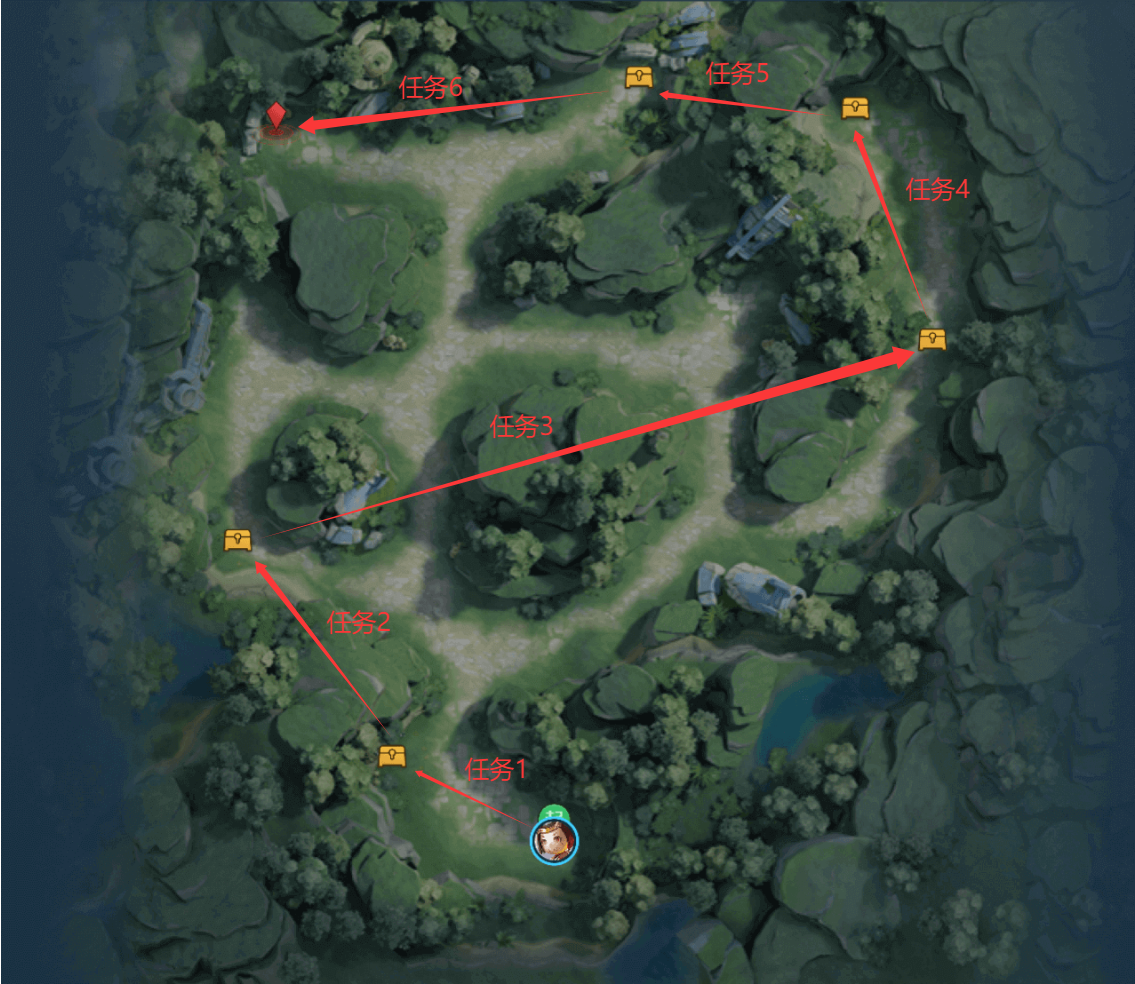
在当前的这个环境里面,我们有6个任务目标,其实不难发现,任务目标数和宝箱数量成正比,并且是宝箱数量+1。其实我们目的就是要让智能体学会的是在面对每次大环境里面的一次次的简单任务。而且不难发现这个任务数量是固定的。其实这个环境的所有随机也都不是真的随机,我们智能体一共只会遇到大概1024个环境。
二、特征处理
特征处理可以直接在原本Q-learning的基础上做微改下就行,比如我的特征处理就是把Q-learning里面的state换成了智能体当前的坐标,然后有一部分做了简单的归一化
# 特征#1: 归一化坐标 |
三、模型和算法
可以参考Pytorch官方的DQN教程:强化学习 (DQN) 教程 — PyTorch 教程 2.7.0+cu126 文档 - PyTorch 深度学习库
除此之外DQN还有很多变体,我这边采用的是Dueling_DQN 和 Double_DQN。除此之外还有、Noisy_Dqn、PPO等等。
强烈推荐Double DQN,这个是训练最稳定的,可以解决目标 Q 值的计算可能导致过度估计的问题。
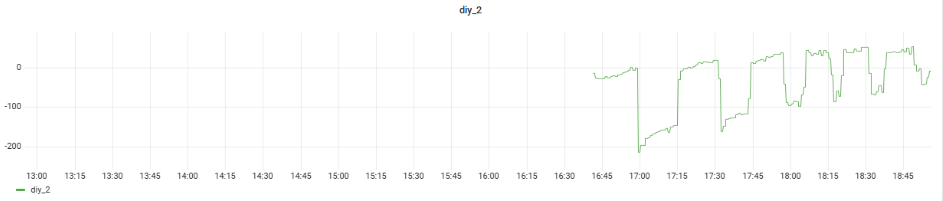
Double_DQN下的目标Q值变化:
其他的:
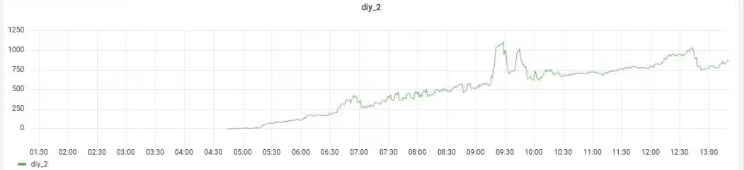
模型设计不需要搞得太花里胡哨了,卷积处理前面特征处理之后的4x5x5的矩阵图,将其他的和卷积处理展平之后的合并再经过全连接用Linear即可。我最终模型的大小是2.11MB。
四、奖励设计
奖励设计才是本次比赛最重要的部分,也是强化学习最具有特色的地方。没有了好的奖励设计,智能体就好比自然环境没有被训练过的野马。
奖励设计我们可以考虑有课程学习的思路,这个推荐可以看看P佬之前分享过的教程,给了我很大的启发。P佬去年的经验贴
我这边说下奖励设计需要额外注意的地方,P佬在教程里面提到过以稠密奖励为骨,稀疏奖励为翼。前者更加重要,也需要思考如何设计。
1、智能体刷奖励
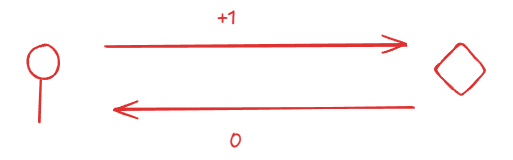
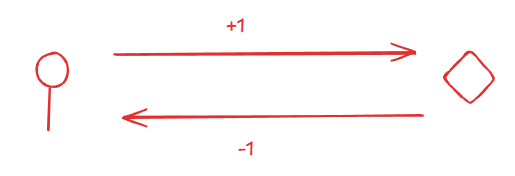
比如这次环境我们要引导智能体靠近当前的最近目标,我们可能常规的想法是智能体只要靠近了目标,奖励就+1。但是其实我们可能忽略了一个很重要的问题,智能体会通过我们这个设计去刷奖励,比如先靠近+1,后远离+0,然后再靠近+1。所以我们应当平衡这个关系,不能让其刷分。
方案一:设计奖励可以靠近+1,远离-1,不动 +0(需要额外惩罚约束)
reward += (prev_dist - cur_dist) * dist_reward
方案二:设计记忆数组,不让刷分,记忆数组里面只允许每次都是最近的。键值最好用离散距离
delta = prev_dist - cur_dist
if delta > 0 and not memory_dist.get(cur_dist):
keys = memory_dist.keys()
if keys:
min_key = min(keys)
if _end_dist < min_key:
memory_dist[cur_dist] = True
reward += delta * dist_reward
else:
memory_dist[cur_dist] = True
reward += delta * dist_reward
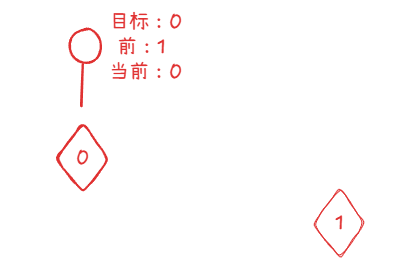
2、智能体目标不一致
- 比如考虑每次到目标位置的时候,我们的目标会进行更换,更换之后就会导致目标不唯一。采用这个设计的话,需要保证每次智能体都是唯一目标,不要出现多目标
if prev_id == cur_id |

五、分布式训练
建议参考以前的文档,或者可以参考以前一个佬开源的当时比赛代码,里面包含原来官方的分布式代码设计。
以前文档的地址:去年的文档
仓库地址:Github-去年代码和大佬的分享
分布式训练我这边没有用attach装饰器,我直接写好对应的SampleData2NumpyData,、NumpyData2SampleData 然后强行替换分布式框架里面的
SampleData = create_cls("SampleData", state=None, next_state=None, action=None, leg_act=None, next_leg_act=None, reward=None, done=None) |
只需要在definition.py里面完成上面对应的代码,然后将下面的这个代码应用到workflow.py和agent.py里面即可
import kaiwu_agent.agent.protocol.protocol as protocol |







